やたら長いタイトルになったのは勘弁してください。「グレープのベントー9を自動でプレイ」の続編?みたいなもの。
今回はTess4Jを使ってOCR(Optical Character Recognition)に挑戦してみた。
・スモークとローネのTURBOって何ですか
ざっくり言うとボキャブラリーのないタイピングゲームである。30秒間にわたって延々と「TURBO」「TA-BO」やキャラクターの名前をキーボードでタイプし続けるゲームである。やってみよう。
プレイ画面はこんな感じだ。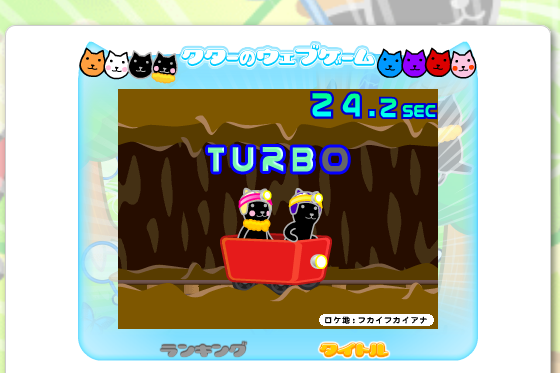
ちょっとフォントが特殊だが、何とかなってほしい。
・画像に前処理をする
文字を認識させやすくするため、輪郭や背景などを取り払ってしまいたい。
今回は都合のいいことに文字の輪郭の内側がグレー(R 102/G 102/B 102)なので、このあたりの色だけを黒く、他を白くして2値化する。
色の操作をしやすいようにこんなメソッドを用意してみた。
public int[] CtoI(int c) { //色を表す整数からARGBの各値へ
int a = c >>> 24;
int r = (c >> 16) & 0xff;
int g = (c >> 8) & 0xff;
int b = c & 0xff;
return new int[] { a, r, g, b };
}
public int ItoC(int[] i) { //ARGBの値から色へ
int c = 0;
for (int e : i)
c = (c << 8) | e;
return c;
}
public int MonoByGray(int[] i) { //2値化
boolean isGray = true;
for (int k = 1; k <= 3; k++)
if (i[k] > 110 || i[k] < 100)
isGray = false;
if (isGray)
return 0xffffffff;
else
return 0xff000000;
}このメソッドを使って、キャプチャーした画像の各ピクセルについて処理していく。
//java.awt.Robotを使ってキャプチャー
BufferedImage orig = robot.createScreenCapture(new Rectangle(ltx, lty, scX, scY));
int w = orig.getWidth(), h = orig.getHeight();
BufferedImage conv = new BufferedImage(w, h, BufferedImage.TYPE_INT_ARGB);
for (int x = 0; x < w; x++) {
for (int y = 0; y < h; y++) {
int c = orig.getRGB(x, y);
int[] rgb = CtoI(c);
conv.setRGB(x, y, MonoByGray(rgb));
}
} 結果はこうなる。結構きちんと2値化できている(本来はモノクロになるはずなのに色がなぜか変になってるが気にしない)。
![]()
![]()
・いざOCR
ここでTess4Jの出番である。下のコードの(1)のところでは、Tess4Jを解凍したフォルダにあるtessdataのパスを指定しないと、InvalidMemoryAccess 例外が出てくるので気を付けよう。
ゲームの処理としては、ゲーム中でタイプする可能性のある単語を配列wordsに格納しておき、tesseract.doOCRで認識された文字列にwordsの中の単語が含まれていれば、それをRobotを使ってタイプするという流れになる(ここではタイプ処理は省略した)。
ITesseract tesseract = new Tesseract();
tesseract.setDatapath("D:\\Tess4J\\tessdata"); //...(1)
tesseract.setLanguage("eng");
String[] words = new String[] {
"TURBO", "BROSSO", "SMOKE", "LOWNE", "TA-BO", "KUTAR",
"CHERRY", "GOLD", "VIP", "GO-RUDO", "NAVY", "BIPPU"
};
try {
String str = tesseract.doOCR(conv);
str = str.replaceAll("(\\n|\\r)", "");
for (String wo : words) {
if (str.contains(wo)) {
//java.awt.Robotでキーボードをタイプする
}
}
} catch (Exception e) {
e.printStackTrace();
return;
}・性能やいかほど
それではできたソフトを実行してみる。
きちんと認識しているっぽい。一安心である。
しかしながら、タイプに成功したときの画面エフェクトが邪魔で思いのほかチートツールとしての性能はよろしくなく、トップランカーよりは弱いという結果になった。これは画像の前処理が杜撰なことを考えれば当然の結果なので、しかるべき処理をすれば性能は向上するかもしれない。
OCRそのものの精度としては、思ったほど良くはなかった。OをC) と間違えたり、OとQの区別がつかなかったり、画像のノイズがピリオドやコンマと認識されたりなど。でもまあこれだけ使えれば十分高性能だと思う。
というわけで初めてのOCRだったがうまくいって満足している。OpenCVとかもやってみたい。
どうでもいいことだが、実行してみた画像にもチラっと「Vip」と見えているように、後継の「クターとチェリーのVIP TURBO」にも対応している。というかキャプチャーする範囲の大きさが違うだけなので、何も特別なことはしていない。