タイプ数カウンターのバイナリデータからデータを引き出す話(需要が皆無)
・どれがどれの数なのかがわからない
タイプ数カウンターというのは、タイプ数をカウントしてくれるフリーソフトである。細かい記録は毎日流れてしまうので、どうせなら毎日分の記録を残してみたいと思ってデータファイルを覗いてみることにした。
データファイルは、タイプ数カウンターの実行ファイル typect.exeと同じフォルダにある data ファイルである。このファイルにはキーボードの記録が入っていて、data2にはマウスの記録が入っている。
さて、このデータファイルはテキストファイルではなくバイナリデータである(メモ帳で開くととんでもないことになる)。データファイルには、記録された数値が unsigned long型で延々とpackされているようなので、これをunpackしてみる。Pythonではstruct.unpackを使うと、結果としてタプルが得られる。
import struct
path="dataのファイルパス"
with open(path,"rb") as f:
b=f.read()
#packされた数値の数を計算する
leng=len(b)//struct.calcsize("L")
fmt=str(leng)+"L"
tup=struct.unpack(fmt,b)結果はこんな感じで、延々と1393個もの数字がズラリ(長すぎるので一部省略している)。
(163, 2018, 7, 22, 4902403, 941680, 460405, 168427, 71076, 27656, 10830, 8030, 7839, 2416, 7464, 5252, 3723, 3006, 5747, 25547, 49075, 82118, 166790, 254470, 256849, 95189, 339212, 627387, 1282215, 32, 0, 0, 0,...198, 43, 91, 141, 0, 0, 0, 145, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 164, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2018, 6, 11, 132882)
2018,7,22とかは日付だとわかるのだが、他の数値はチンプンカンプンでどれがどれだか分からない。このおよそ1400個の数字が何を表しているのか突き止めるために、特定キーを連打して値の変化を見たり、カウンターに表示されている値と照らし合わせてみたりした結果、ある程度はどうなっているか分かった。
・調査結果
まず大まかな区分を見てみよう。
| 区分 | 値の数 |
|---|---|
| カウント日数 | 1 |
| 今日の日付 | 3 |
| 合計打鍵数 | 1 |
| 合計打鍵数(1時間ごと) | 24 |
| 合計打鍵数(キーごと) | 256 |
| 今日の打鍵数 | 1 |
| 今日の打鍵数(1時間ごと) | 24 |
| 今日の打鍵数(キーごと) | 256 |
| 不明(カウント週数か?) | 2 |
| 合計打鍵数(曜日ごと) | 7 |
| 今週の打鍵数(曜日ごと) | 7 |
| 今週の打鍵数(キーごと) | 256 |
| 昨日のカウント日数 | 1 |
| 昨日の日付 | 3 |
| 昨日の打鍵数 | 1 |
| 昨日の打鍵数(時間ごと) | 24 |
| 昨日の打鍵数(キーごと) | 256 |
| 不明 | 2 |
| 先週の打鍵数 | 1 |
| 先週の打鍵数(曜日ごと) | 7 |
| 先週の打鍵数(キーごと) | 256 |
| 打鍵数最大の日付 | 3 |
| 1日当たり最大打鍵数 | 1 |
さらに、「キーごと」の256個の値は、各キーと以下のように対応する。値の無いところは不明なキーである。
| 順番 | キー |
|---|---|
| 1 | その他 |
| 9 | BackSpace |
| 10 | Tab |
| 14 | Enter |
| 17 | Shift |
| 18 | Ctrl |
| 19 | Alt |
| 20 | Pause/Break |
| 21 | Caps |
| 28 | Esc |
| 29 | 変換 |
| 30 | 無変換 |
| 33 | Space |
| 34 | PageUp |
| 35 | PageDown |
| 36 | End |
| 37 | Home |
| 38 | Left |
| 39 | Up |
| 40 | Right |
| 41 | Down |
| 45 | PrintScreen |
| 46 | Insert |
| 47 | Delete |
| 49 - 58 | 0 - 9 |
| 66 - 91 | A - Z |
| 92 | Win(L) |
| 93 | Win(R) |
| 97 - 106 | テンキー0 - テンキー9 |
| 107 | テンキー* |
| 108 | テンキー+ |
| 109 | テンキー, |
| 110 | テンキー- |
| 111 | テンキー. |
| 112 | テンキー/ |
| 113 - 124 | F1 - F12 |
| 145 | NumLock |
| 146 | ScrollLock |
| 187 | : |
| 188 | ; |
| 189 | , |
| 190 | - |
| 191 | . |
| 192 | / |
| 193 | @ |
| 220 | [ |
| 221 | ¥ |
| 222 | ] |
| 223 | ^ |
| 227 | \ |
| 243 | カタカナ/ひらがな |
| 244 | 全角/半角 |
不明の値が150個もある(半分以上!)。たぶん数字とかアルファベットをASCIIコードと多少対応させるためにパディングしてるんだろうと思う。一部のキーは今使っているキーボードには存在しなかったので調査を断念した。有志による報告をお待ちしております。
・何かしら見やすい形に出力する
CSVとjsonで出力してみよう。
import json
indexes=(
("today/daycount",1),("today/date",3),
("overall/all",1),("overall/hour",24),("overall/key",256),
("today/all",1),("today/hour",24),("today/key",256),
("unknown/1",2),
("overall/day",7),("thisweek/day",7),("thisweek/key",256),
("yesterday/daycount",1),("yesterday/date",3),("yesterday/all",1),
("yesterday/hour",24),("yesterday/key",256),
("unknown/2",2),
("lastweek/all",1),("lastweek/day",7),("lastweek/key",256),
("max/date",3),("max/all",1)
)
# キー名、不明な区間の長さ
keyname=(
"others",7,"Bcsp","Tab",3,"Enter",2,"Shift","Ctrl","Alt","Pause",
"Caps",6,"Esc","変換","無変換",2,"Space","PgUp","PgDn","End","Home",
"Left","Up","Right","Down",3,"PrtSc","Insert","Delete",1,
"0","1","2","3","4","5","6","7","8","9",7,
"A","B","C","D","E","F","G","H","I","J","K","L","M","N",
"O","P","Q","R","S","T","U","V","W","X","Y","Z",
"Win(L)","Win(R)",3,
"Ten_0","Ten_1","Ten_2","Ten_3","Ten_4","Ten_5",
"Ten_6","Ten_7","Ten_8","Ten_9",
"Ten_*","Ten_+","Ten_,","Ten_-","Ten_.","Ten_/",
"F1","F2","F3","F4","F5","F6","F7","F8","F9","F10","F11","F12",20,
"NumLk","ScrLk",40,":",";",",","-",".","/","@",26,"[","Yen","]",
"^",3,"\\",15,"カタカナ/ひらがな","全角/半角",12
)
dayname=("Sun","Mon","Tue","Wed","Thu","Fri","Sat")
# タプルを受け取って辞書/値に変換
def TupleToDict(tup,content):
if content=="all" or content=="daycount":return tup[0]
if content=="date":return "%d/%d/%d"%tup
if content=="hour":return {i:tup[i] for i in range(24)}
if content=="day":return {dayname[i]:tup[i] for i in range(7)}
if content=="key":
rp=0
dic={}
for key in keyname:
if type(key)==int:rp+=key # 不明な区間をスキップ
else:
dic[key]=tup[rp]
rp+=1
return dic
# 出力するデータ
dic_o={
"overall":{},
"today":{},
"yesterday":{},
"thisweek":{},
"lastweek":{},
"max":{}
}
rp=0
for index in indexes:
sp=index[0].split("/")
period=sp[0]
content=sp[1]
dlen=index[1]
dpart=tup[rp:rp+dlen] # 区分ごとにスライス
rp+=dlen
if period=="unknown":continue
dic_o[period][content]=TupleToDict(dpart,content)
# 辞書からCSV
csv=",overall,today,yesterday,this week,last week\n"
csv+="Total,%d,%d,%d,,%d\n"%(
dic_o["overall"]["all"],dic_o["today"]["all"],
dic_o["yesterday"]["all"],dic_o["lastweek"]["all"])
for key in keyname:
if type(key)==int:continue
csv+="%s,%d,%d,%d,%d,%d\n"%(
key,dic_o["overall"]["key"][key],
dic_o["today"]["key"][key],dic_o["yesterday"]["key"][key],
dic_o["thisweek"]["key"][key],dic_o["lastweek"]["key"][key])
path_csv="保存ファイルパス.csv"
with open(path_csv,"w") as fc:
fc.write(csv)
path_json="保存ファイルパス.json"
with open(path_json,"w") as fj:
json.dump(dic_o,fj)CSVのところが汚いコードになってしまったが勘弁してほしい。見た目はこんな感じになる。
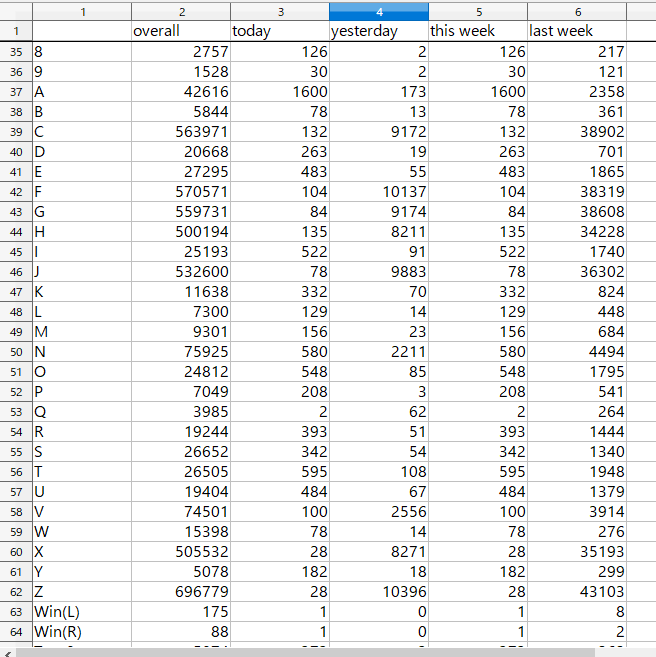
BMSとかいうクソゲーのせいで特定のキーだけ打鍵数が桁違いに多くなってしまった。
というわけで無事データを抽出できた。毎日記録を残すのであれば、「昨日」の分だけ抽出するようにして、バッチファイルをタスクスケジューラにでもぶち込んでおけばいいと思う。
だいぶ以前に書かれた記事に関してのご質問になってしまい大変恐縮ですが、どうかお許しください。私はプログラミングは初心者でこの記事に書かれている内容以前の質問になっていましたら申し訳ないのですが、このデータがunsigned long型で記録されてるのでstrict.unpackで"L"を選択していらっしゃると思うのですが、私がやってみたところ、Lですとデータが100バイトより小さいサイズの時でしか実行できませんでした。どのように対処されましたでしょうか?
コメントの確認が遅れてすみません。実際のデータとコードを見ていないので詳しいことはわかりませんが、unpackするにあたってデータ長の制約はないはずなので、リファレンスを参照して、フォーマットの指定が合っているか確認されるとよいと思います。
https://docs.python.org/ja/3/library/struct.html